Externe Daten
PhraseExpress kann Daten aus externen Dateien oder Onlinediensten in einen Textbaustein einbetten.
Sprachübersetzung
PhraseExpress unterstützt Onlinedienste, wie DeepL oder OpenAI zur Übersetzung von Texten per Makrofunktion in die angegebene Zielsprache.
Sofern keine Quellsprache angegeben ist, analysiert der Übersetzungsalgorithmus den Text, um die Sprache des Textes automatisch zu bestimmen.
AI Textbearbeitung
Das Makro "KI Textbearbeitung" ermöglicht die Nutzung von künstlicher Intelligenz ("KI") in jeder Anwendung:
Im Makrodialog definieren Sie die Eingabe, also den Text der von OpenAI bearbeitet werden soll und die Anweisung in natürlicher Sprache, wie OpenAI den Text verarbeiten soll.
Über das Zahnradsymbol können Sie das gewünschte Sprachmodell wählen und weitere AI Parameter konfigurieren.
Die wahre Stärke liegt in der Kombination des KI Makros mit weiteren PhraseExpress Makrofunktionen. Mit einem Rechtsklick in eines der Eingabefelder können Sie eine PhraseExpress Makrofunktion in das KI-Makro einfügen.
Sie können das Eingabe leer lassen und die KI auffordern, einen Text zu generieren, statt einen bestehenden Text zu bearbeiten; z.B. "schreibe ein zufälliges Keksrezept".
KI Parameter
Parameter für große Sprachmodelle (LLMs) werden verwendet, um verschiedene Aspekte ihrer Leistung, ihres Verhaltens und ihrer Ausgabe zu steuern.
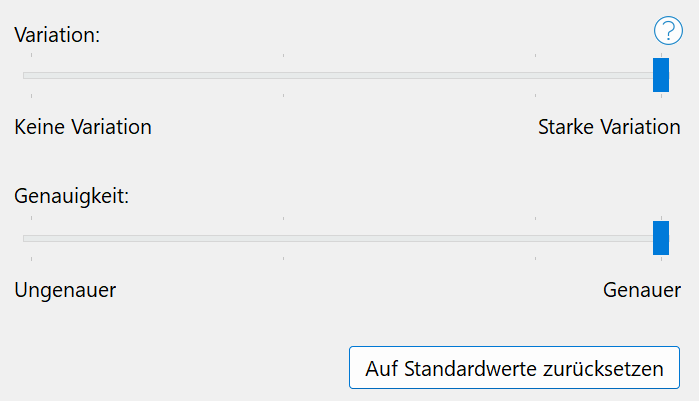
Variation
Der Parameter "" (auch als "Temperatur" bezeichnet) beeinflusst die Vielfalt und Unvorhersehbarkeit der KI-generierten Ausgabe. Er steuert, wie stark das Modell von den wahrscheinlichsten Antworten abweicht. Eine höhere Variation führt zu kreativeren, aber potenziell weniger kohärenten Ergebnissen, während eine niedrigere Variation zu präziseren, aber möglicherweise weniger innovativen Antworten führt.
- Starke Variation: Mehr Vielfalt, kreativere Ausgaben, erhöhtes Risiko unzusammenhängender oder unpassender Antworten.
- Keine Variation: Weniger Vielfalt, präzisere und vorhersehbare Ausgaben, reduziertes Risiko unpassender Antworten.
Genauigkeit
Der Parameter "" in einem KI-Modell bezieht sich typischerweise auf die Fähigkeit des Modells, Eingaben basierend auf den gegebenen Daten korrekt vorherzusagen oder zu klassifizieren. Genauigkeit ist eine entscheidende Metrik zur Bewertung der Leistung eines Modells, insbesondere bei Klassifikationsaufgaben.
Eine hohe Genauigkeitseinstellung hat weitgehend positive Auswirkungen, insbesondere in Bezug auf die Leistungsfähigkeit und Zuverlässigkeit des Modells:
- Korrekte Vorhersagen: Eine hohe Genauigkeit bedeutet, dass das Modell die meisten Vorhersagen oder Klassifikationen korrekt macht. Dies ist besonders vorteilhaft in kritischen Anwendungen wie medizinische Diagnosen, Betrugserkennung oder autonomes Fahren.
- Vertrauen und Zufriedenheit der Nutzer: Nutzer haben mehr Vertrauen in das System, wenn es konsistent korrekte Ergebnisse liefert. Dies kann zu höherer Nutzerzufriedenheit und Akzeptanz der Technologie führen.
- Geschäftliche Vorteile: Für Unternehmen kann eine hohe Genauigkeit zu gesteigerter Effizienz, Kosteneinsparungen und verbesserter Reputation führen. Zum Beispiel können im E-Commerce präzise Produktempfehlungen zu besseren Kundenerfahrungen und höheren Umsätzen beitragen.
- Ressourceneffizienz: Ein Modell mit hoher Genauigkeit maximiert den Nutzen der investierten Rechenressourcen, Zeit und Aufwand und reduziert den Bedarf an zusätzlicher Nachbearbeitung oder menschlichem Eingreifen.
- Minimierung von Schäden: In kritischen Anwendungen wie Gesundheitswesen, rechtlichen Entscheidungen oder Sicherheit kann eine hohe Genauigkeit schwerwiegende Konsequenzen wie Fehldiagnosen, falsche Verurteilungen oder Sicherheitsverletzungen verhindern.
- Reduzierte Fehlerkorrektur: Modelle mit hoher Genauigkeit erfordern weniger Nachbearbeitung und menschliches Eingreifen, was die Gesamtkosten und Komplexität des Systems senkt.
- Positive Feedback-Schleifen: In Anwendungen, die Feedback-Schleifen nutzen, wie Empfehlungssysteme, können präzise Vorhersagen die zukünftige Leistung des Modells verbessern, indem korrekte Empfehlungen zukünftige Vorhersagen positiv beeinflussen.
Zusammenfassend führt eine hohe Genauigkeitseinstellung zu besserer Leistung, höherer Nutzerzufriedenheit, geschäftlichen Vorteilen und geringeren Kosten . Es ist jedoch wichtig sicherzustellen, dass die hohe Genauigkeit nicht durch "Overfitting" auf die Trainingsdaten erreicht wird und dass das Modell gut auf neuen, unvorhergesehenen Daten generalisiert.
Eine niedrige Genauigkeitseinstellung hat mehrere bedeutende Auswirkungen, insbesondere in Bezug auf seine Leistung und Zuverlässigkeit:
- Falsche Vorhersagen: Eine niedrige Genauigkeit bedeutet, dass das Modell mehr falsche Vorhersagen oder Klassifikationen macht. Dies kann in Anwendungen, in denen Präzision entscheidend ist, wie medizinische Diagnosen, Betrugserkennung oder autonomes Fahren, schädlich sein.
- Vertrauen und Zufriedenheit der Nutzer: Nutzer verlieren wahrscheinlich das Vertrauen in das System, wenn es häufig Fehler macht. Dies kann zu einer geringeren Zufriedenheit und Zurückhaltung bei der Nutzung der Technologie führen.
- Geschäftliche Auswirkungen: Für Unternehmen kann eine niedrige Genauigkeit finanzielle Verluste, Ineffizienzen und Rufschäden zur Folge haben. Zum Beispiel können im E-Commerce ungenaue Produktempfehlungen zu schlechten Kundenerfahrungen und verlorenen Umsätzen führen.
- Ressourcenverschwendung: Die fortgesetzte Nutzung eines Modells mit niedriger Genauigkeit kann Rechenressourcen, Zeit und Aufwand verschwenden, die besser für die Entwicklung oder den Einsatz eines genaueren Modells verwendet werden könnten.
- Potentieller Schaden: In kritischen Anwendungen wie Gesundheitswesen, rechtlichen Entscheidungen oder Sicherheit kann eine niedrige Genauigkeit ernsthafte Konsequenzen haben, wie Fehldiagnosen, falsche Verurteilungen oder Sicherheitsverletzungen.
- Notwendigkeit für Nachbearbeitung: Modelle mit niedriger Genauigkeit erfordern möglicherweise zusätzliche Nachbearbeitung oder menschliches Eingreifen zur Fehlerkorrektur, was die Gesamtkosten und Komplexität des Systems erhöht.
- Fehlausrichtung von Leistungsmetriken: Abhängig vom Kontext kann es irreführend sein, sich ausschließlich auf die Genauigkeit zu verlassen. Bei unausgewogenen Datensätzen könnte ein Modell eine hohe Genauigkeit erreichen, indem es die Mehrheitsklasse vorhersagt, aber die Instanzen der Minderheitsklasse nicht korrekt identifiziert. In solchen Fällen sind andere Metriken wie Präzision, Recall und F1-Score ebenfalls entscheidend.
- Probleme mit Feedback-Schleifen: In Anwendungen, die Feedback-Schleifen nutzen, wie Empfehlungssysteme, können Fehler einer niedrigen Genauigkeit propagiert werden, was zu einer verschlechterten Leistung im Laufe der Zeit führt, da falsche Empfehlungen zukünftige Vorhersagen beeinflussen.
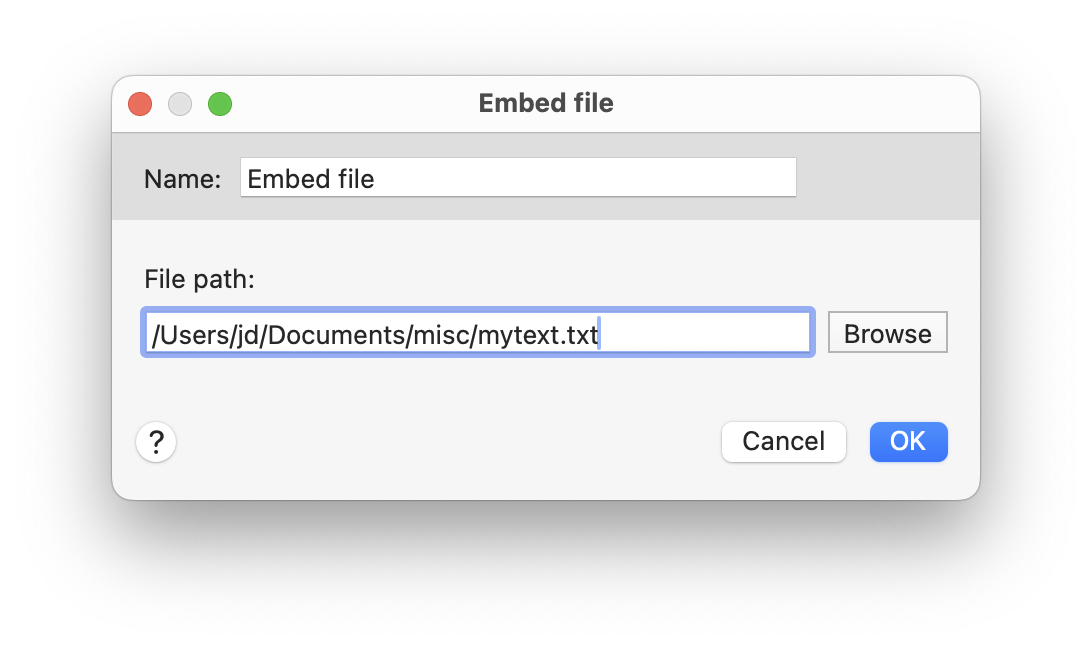
Einfügen externer Dateiinhalte
Diese Makrofunktion fügt den Inhalt der angegebene Datei im Moment des Ausführens des Textbausteins in den Textbaustein ein:
CSV Werte
Diese Makrofunktion fügt die Zelle(n) einer CSV-Datei ("comma separated values", englisch für "kommagetrennte Werte") dynamisch im Moment des Ausführens des Textbausteins ein:
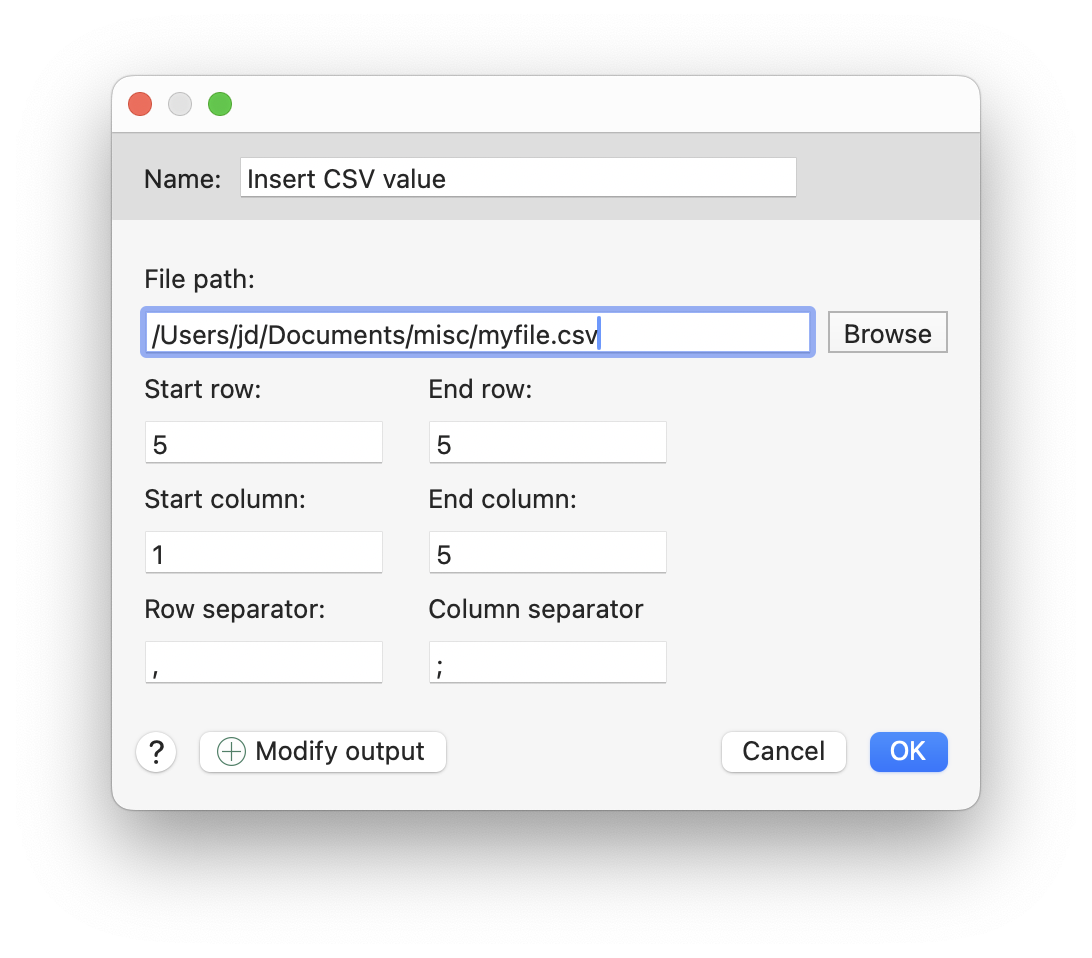
Parameter:
- "Zeile" und "Spalte" definieren die Koordinate des auszulesenden Wertes (jeweils ab Zahl 1).
- Bei optionaler Angabe von Endzeile und/oder Endspalte werden die Werte bis zur jeweiligen Koordinate ausgegeben (jeweils ab Zahl 1). Wird sowohl eine Endspalte und Endzeile angegeben, werden die entsprechenden Zellen des Ausschnitts der CSV-Datei von "links oben bis rechts unten" ausgegeben.
- Bei Ausgabe mehrerer Zellen einer Zeile werden diese optional mit dem unter Spaltenseparator angegebenen Zeichen aneinandergereiht ausgegeben.
- Bei Ausgabe mehrerer Zellen einer Spalte werden diese optional mit dem, mit "Zeilenseparator" definierten Trenntext aneinandergereiht ausgegeben.
XML Wert
Diese Makrofunktion fügt den, per XPath adressierten Wert einer XML-Datei dynamisch im Moment des Ausführens des Textbausteins ein.